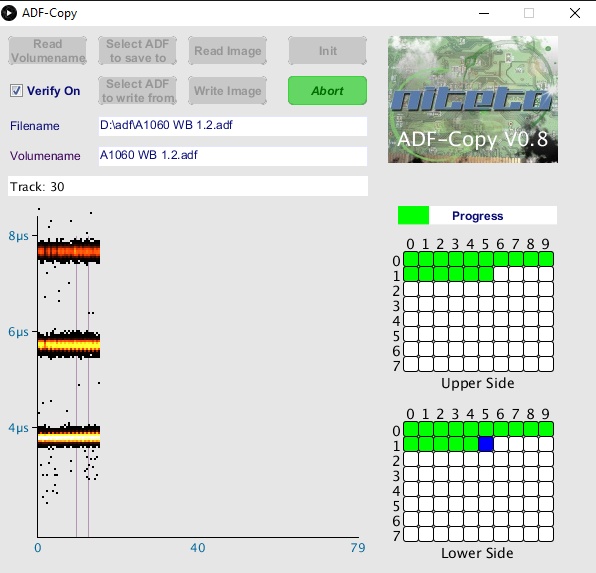
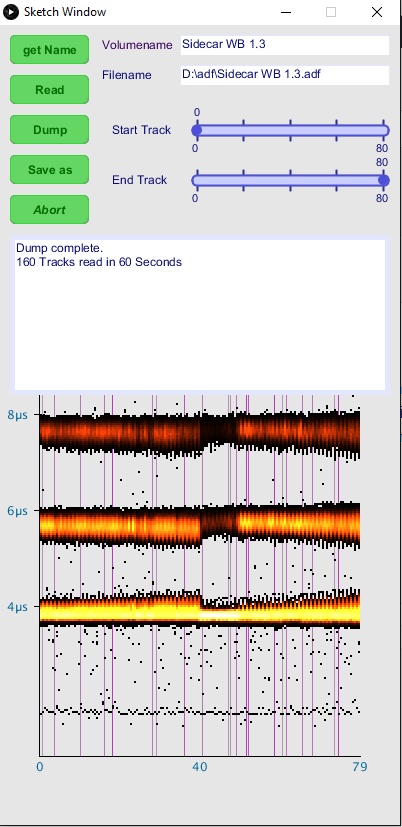
Ich war mal wieder fleißig und habe in das Frontend Support für Linux und Raspberry Pi hinzugefügt. Ebenso das Interface mit hübscheren Buttons versehen und etwas schlanker gemacht.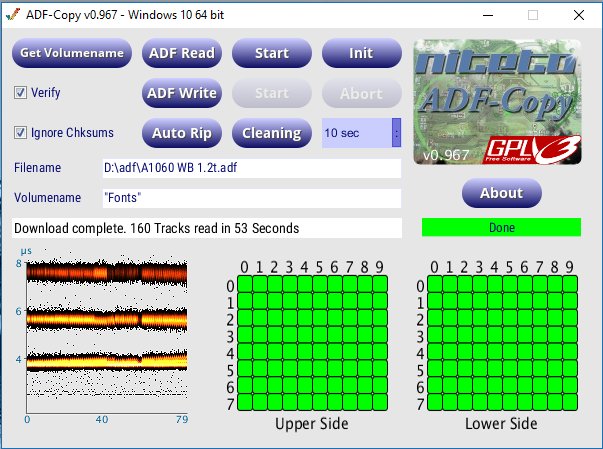
Die App setzt auf allen Systemen eine saubere Java Runtime Envoronment (JRE) 8.x Installation voraus. Ich habe auf folgenden Platformen getestet:
Raspberry Pi 3 Model B, Ubuntu 16.04.1 Desktop amd64, Windows 7 32 bit, Windows XP Home, Windows 10 Home.
Bei WIndows XP und vermutlich Vista ist darauf zu achten das man die Seriellen Treiber für den Teensy installiert – http://www.pjrc.com/teensy/td_download.html
Bei Linux sollte man die udev rules installieren weil man sonst ohne root rechte nicht auf den seriellen Port des Teensy zugreifen kann.
Die App gibts im Download Bereich.
Have Fun!